

Understanding Snowflake Architecture: The Foundation of the Modern Data Cloud
Introduction
In the rapidly evolving world of cloud data platforms, Snowflake has established itself as a leading solution for organizations seeking scalability, performance, and operational simplicity in analytics. Snowflake’s value does not stem solely from SQL compatibility or managed service convenience; it is the platform’s underlying design — the Snowflake Architecture — that enables its distinctive capabilities.
This article examines Snowflake’s architecture in depth. It explains the three core layers, contrasts Snowflake’s hybrid approach with traditional shared-disk and shared-nothing architectures, and highlights operational and cost implications for enterprise systems.
Evolution toward Cloud-Native Architecture
Shared-Disk and Shared-Nothing: A brief comparison
Two classic architectures dominated early enterprise systems:
- Shared-disk: Multiple compute nodes access a centralized disk. Data management is simplified, but contention and bottlenecks can limit performance under heavy load.
- Shared-nothing: Each node manages its own storage and memory. This model scales well for parallel processing but complicates data consistency and sharing.
Snowflake’s hybrid approach
Snowflake combines the centralized, single-source-of-truth storage model with massively parallel processing at the compute layer. The result is a platform that preserves data management simplicity while delivering the scale and isolation benefits of shared-nothing compute.
Restaurant Analogy: A Practical Lens
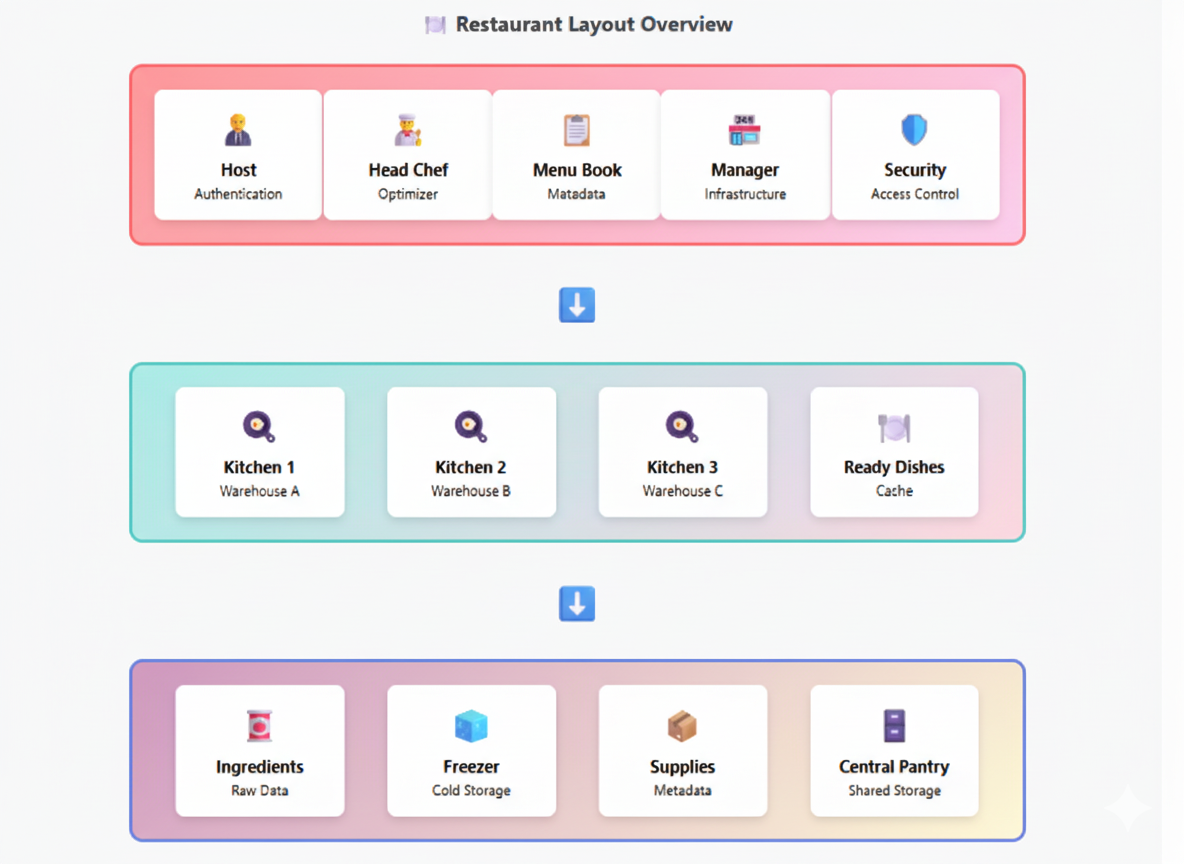
A concise analogy clarifies Snowflake’s separation of responsibilities:
- Storage layer (kitchen pantry): All ingredients are stored and organized in the kitchen.
- Compute layer (chefs): Chefs prepare meals on demand, using ingredients from the pantry. More chefs can be brought in at peak times.
- Services layer (manager): The manager coordinates orders, staff, reservations, and security.
This separation permits rapid scaling of staff (compute) without rebuilding the kitchen (storage) or changing inventory, enabling elasticity and predictable management.
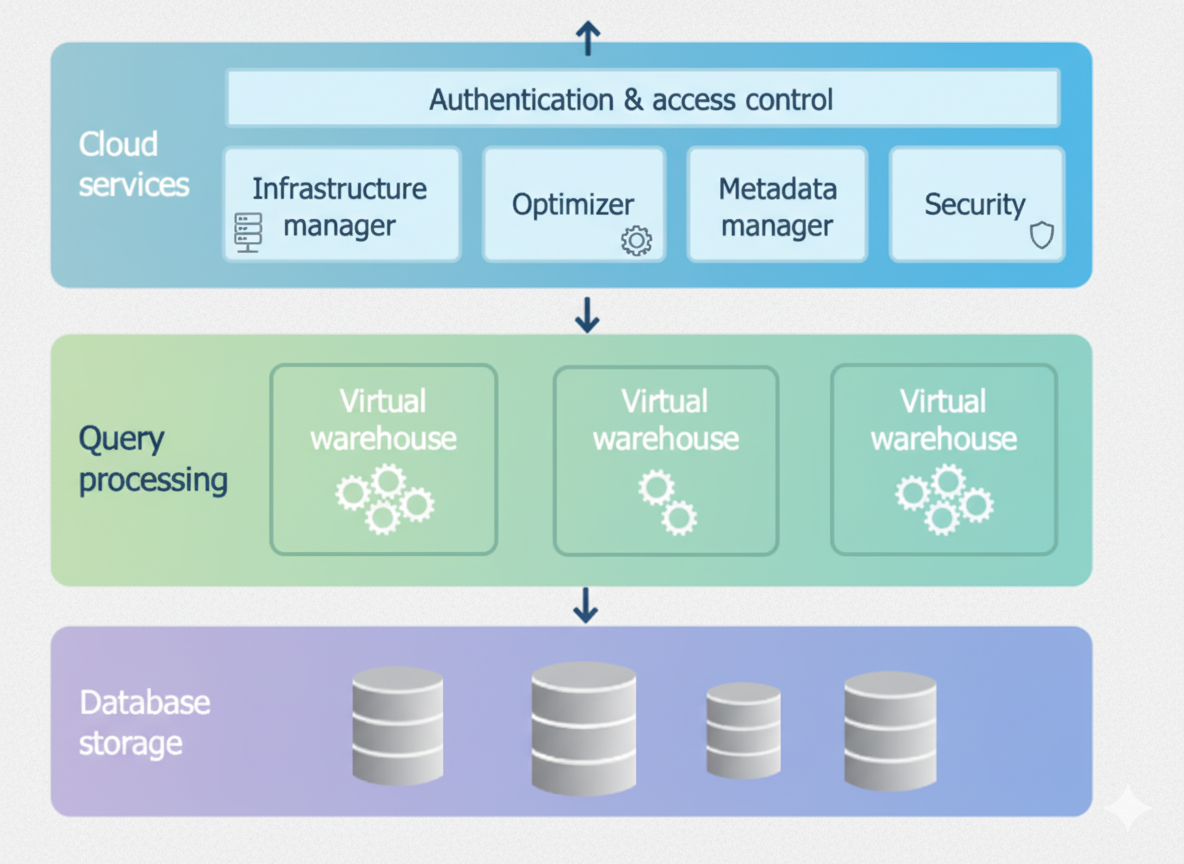
Snowflake’s Three-Layer Architecture
Snowflake’s architecture consists of three distinct layers that together provide the platform’s operational characteristics:
- Database Storage Layer
- Query Processing Layer (Compute)
- Cloud Services Layer (Control Plane)
Database Storage Layer
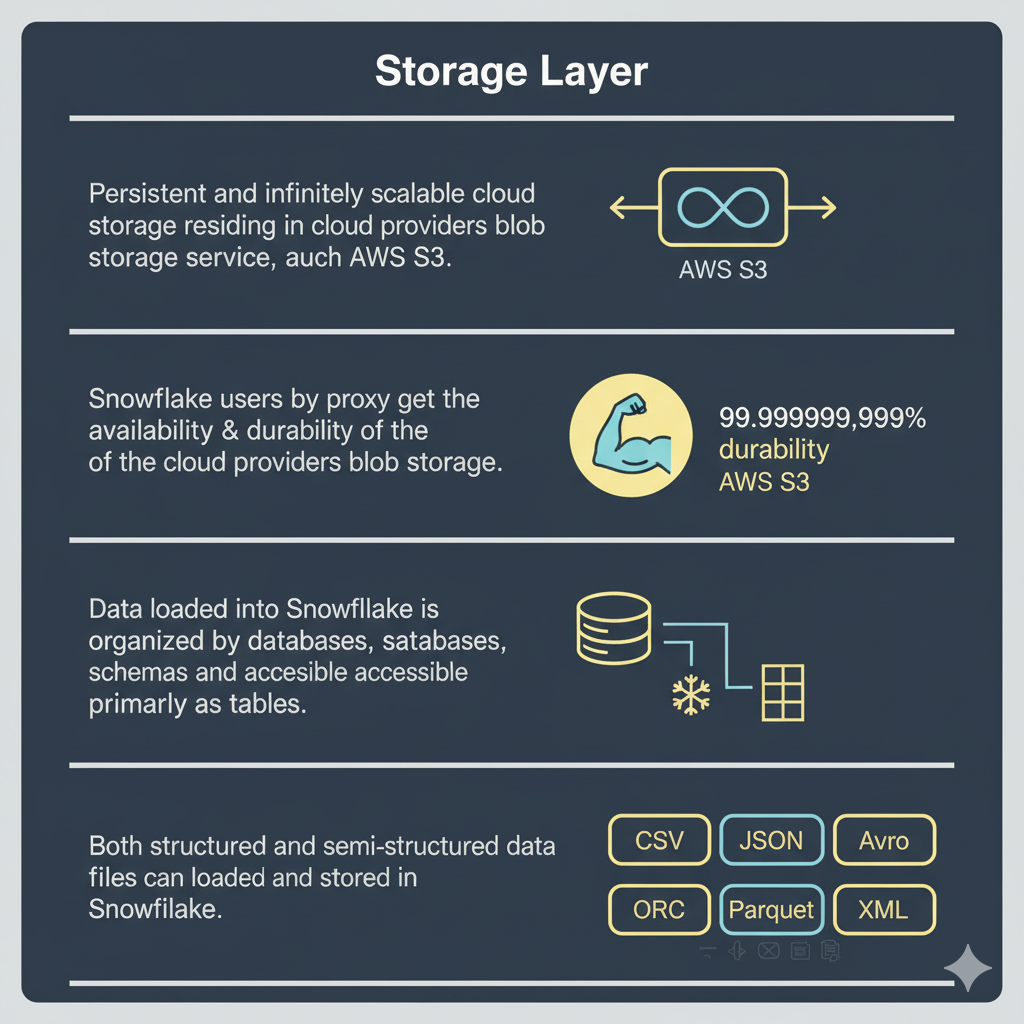
The storage layer is the persistent foundation. Snowflake stores both structured and semi-structured data in a compressed, columnar format in cloud object storage (for example, AWS S3, Azure Blob Storage, or Google Cloud Storage).
Key attributes:
- Data is organized into micro-partitions and compressed for storage efficiency.
- Storage is centralized and accessible by all compute clusters.
- Snowflake handles data organization, indexing, and metadata management automatically.
- Support for zero-copy cloning and near-instant snapshots.
CREATE DATABASE sales_db;
CREATE SCHEMA q1_analysis;
CREATE TABLE orders (order_id INT, product STRING, price FLOAT);Users interact with this layer exclusively via SQL. Raw file formats (CSV, JSON, Parquet, Avro, ORC) can be loaded and are converted into Snowflake’s internal representation.
Query Processing Layer (Compute)

Compute is provided by Virtual Warehouses. Each virtual warehouse is a cluster of compute nodes provisioned from the cloud provider and dedicated to specific workloads.
Key attributes:
- Massively parallel execution (MPP) for SQL statements.
- Workload isolation: separate warehouses operate independently and do not contend for compute resources.
- Elasticity: warehouses can be resized, suspended, or scaled out to meet demand.
- Billing is based on compute runtime (credits), enabling pay-per-use cost control.
CREATE WAREHOUSE analytics_wh
WAREHOUSE_SIZE = 'LARGE'
AUTO_SUSPEND = 300
AUTO_RESUME = TRUE;
ALTER WAREHOUSE analytics_wh RESUME;
SELECT region, SUM(revenue) FROM sales_db.public.orders GROUP BY region;Cloud Services Layer (Control Plane)
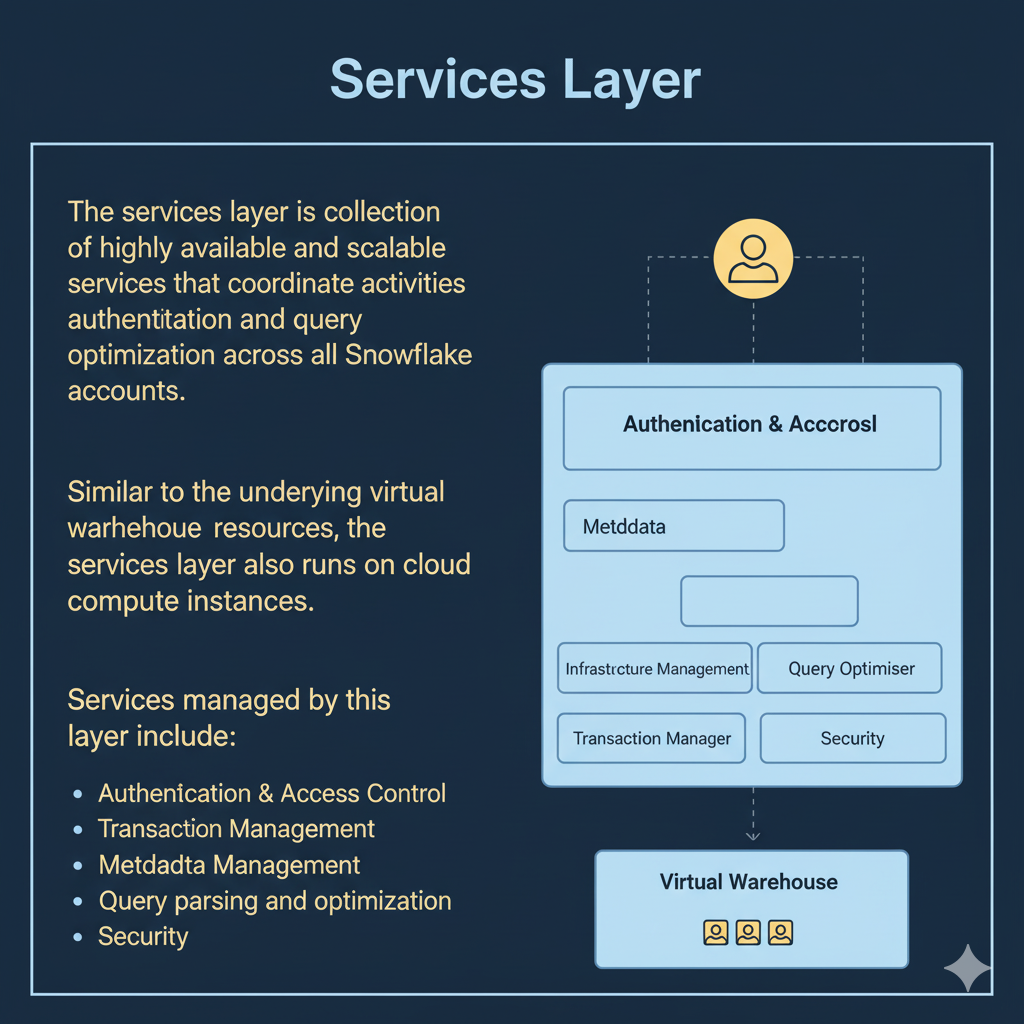
The cloud services layer acts as Snowflake’s control plane. It is responsible for authentication, metadata management, query parsing and optimization, security, and infrastructure orchestration.
Key responsibilities:
- Authentication and RBAC (roles, privileges).
- Query optimization and plan selection.
- Metadata storage and management (schemas, object definitions, statistics).
- Service orchestration and logging.
All of these services run on Snowflake-managed compute instances within the chosen cloud provider and are abstracted from the user.
How the Layers Interact
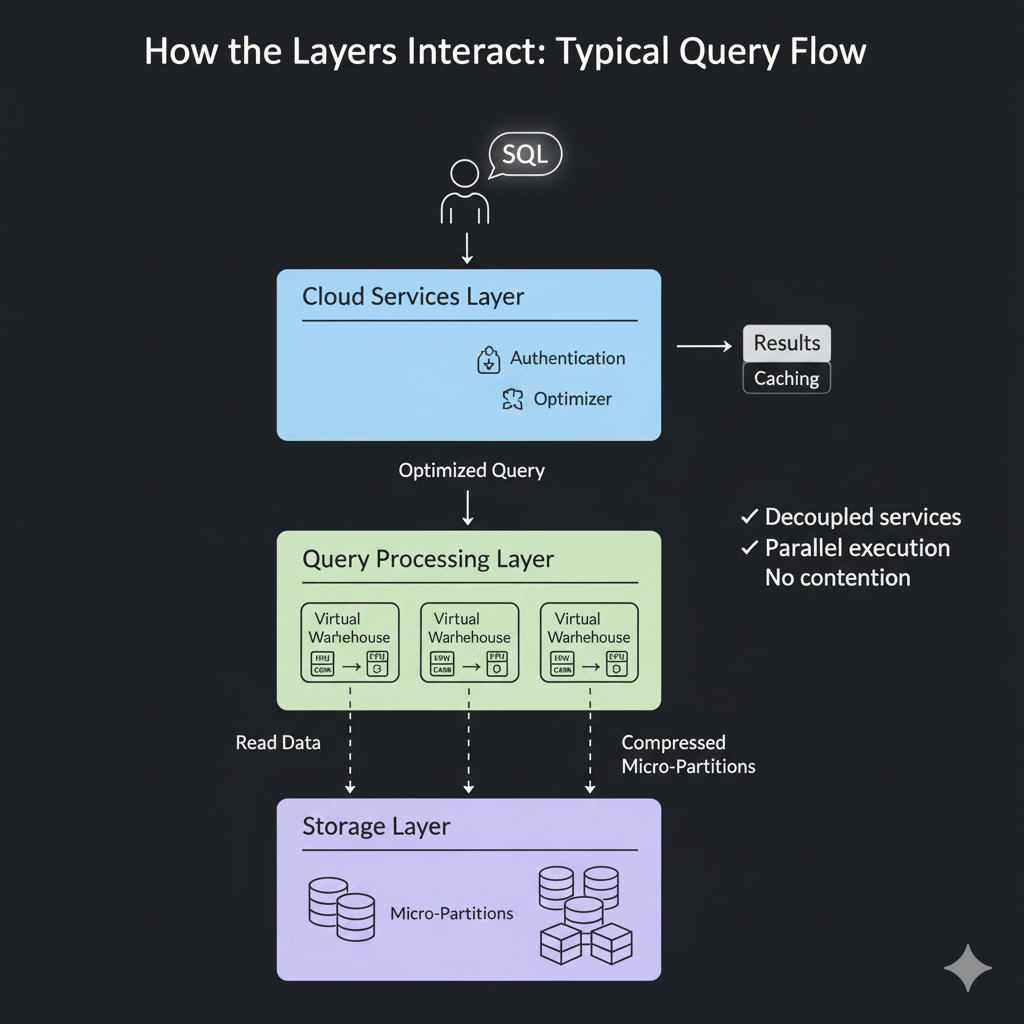
Typical query flow:
- User authenticates and submits SQL. The cloud services layer parses and optimizes the query.
- The query processing layer (a virtual warehouse) executes the optimized plan and reads compressed micro-partitions from the storage layer.
- Results are returned to the client. Caching may be used to accelerate repeat queries.
This flow preserves strong separation of concerns and enables parallel work without contention.
Concurrency and Caching
Snowflake uses multiple caching tiers: result cache, local warehouse cache, and metadata caches. Result cache can return results instantly if the exact same query is submitted and underlying data has not changed, while warehouse local caches speed up repeated operations within a running warehouse.
Advantages and Practical Implications
Elasticity and Cost Efficiency
Compute can be scaled dynamically to match workload needs. Organizations pay for compute only while warehouses run, and storage is billed separately. This decoupling enables cost optimization: scale down during idle periods and scale up for peak loads.
Workload Isolation and Concurrency
Virtual warehouses isolate workloads, enabling heavy ETL jobs and interactive BI queries to run in parallel without affecting each other. Multi-cluster warehouses can provide autoscaling for concurrency spikes.
Operational Simplicity
Snowflake manages infrastructure maintenance, upgrades, and storage optimization. Teams can focus on data engineering and analytics rather than hardware and low-level tuning.
Data Sharing and Collaboration
Centralized storage, together with secure sharing mechanisms, enables cross-account or cross-organization data sharing without data duplication. Zero-copy cloning reduces storage overhead for sandboxes and testing.
Real-World Example: Scaling for Quarterly Reporting
A retail company must support heavy reporting at quarter-end. Traditional architectures would require provisioning additional hardware or scheduling complex maintenance windows. With Snowflake:
- Administrators increase the warehouse size or enable multi-cluster scaling during the reporting window.
- After the peak period, warehouses are scaled down or suspended to reduce costs.
ALTER WAREHOUSE reporting_wh
SET WAREHOUSE_SIZE = 'XLARGE';
ALTER WAREHOUSE reporting_wh
SET MIN_CLUSTER_COUNT = 1, MAX_CLUSTER_COUNT = 4;This approach shortens time-to-insight and minimizes infrastructure costs.
Security, Governance, and Durability
Snowflake enforces encryption in transit and at rest, supports role-based access control, and offers features such as masking policies, row-access policies, and object-level privileges. Storage durability leverages cloud provider guarantees, ensuring high durability for persisted data.
Governance features and metadata capture enable auditing and cost monitoring while preserving fine-grained access controls for sensitive data.
When Snowflake Architecture Is Especially Beneficial
- Organizations requiring rapid elasticity for variable workloads.
- Teams needing high concurrency for BI and analytics alongside heavy ETL jobs.
- Use cases that benefit from zero-copy cloning and secure data sharing across teams or partners.
- Environments where operational simplicity and managed services reduce total cost of ownership.
Conclusion
Snowflake Architecture represents a paradigm shift in cloud data warehousing. By combining centralized, durable storage with isolated, elastic compute and a powerful control plane, Snowflake delivers performance, concurrency, and operational simplicity that traditional architectures struggle to match.
For data engineers and architects, Snowflake’s layered model facilitates predictable performance, cost control, and rapid iteration — enabling modern analytics at scale without the operational overhead of managing infrastructure.